Online Judge 是如何解决判题端安全性问题的?
21 个回答
几个错误做法:
- 所有的字符串过滤都是耍流氓,坑人坑自己:C语言强大的宏几乎没有绕不过的字符串过滤,而且误伤也是很常见的(我就见过小白 OIer 问为什么程序老是被判非法,结果一看里头有个变量叫做 fork )。
- 手 +工审计头文件,去掉某些头文件或者注释掉一些部分是辛苦且无用的:做了这样的工作之后,你就几乎再也不会想去升级编译器及头文件了,更可怕的是——这个工 +作需要你对语言、编译器、连接器有一定程度的了解,而我认为拥有足够了解的人都应该知道这是不靠谱的:就算没有头文件、没有了函数原型,调用系统调用的方 +法还是有一大把而且都不是很麻烦。
准备工作:
- 熟悉你的目标系统(Windows or Linux):
- 必须要了解这个平台下的原生系统调用 API 是怎么使用的(不然你要怎么屏蔽?),最好可以了解到汇编层面。
- 必须要了解这个平台下的用户系统、权限控制、资源限制。
- 最好要了解一下进程跟踪/调试/监控工具或者系统调用,例如 Linux 下的 ptrace 。
- 最好要了解目标系统提供的各种沙盒限制功能。
- 了解你的编程语言及工具链:
- 必须要了解你的目标语言的特性,及其在一般的 OI / ACM 比赛中的规定、限制。
- 必须要了解你的工具链的功能及各种参数。
- 拥有足够的编程功底,对于这样小的程序,应当严格杜绝缓冲区溢出之类的 bug 。
然后我再说说我的做法,在其中大家就可以看到上面列的这些“准备知识”是如何派上用场的。我的目标平台是 Linux ,目标语言是 Pascal 、 C 、 C++ 。
我采取了以下措施:
- 操作系统层面:
- 时间、资源的限制:
- 内存:我使用了 rlimit 进行控制,同时也方便在运行结束后获得内存使用情况的数据,不过有一个“缺点”就是如果是声明了一个超大的空间但从未访问使用就不会被统计进来(经过观察发现很多 ACM 或者 OI 比赛也都是这么处理的,所以应该不算是一个问题)。
- 时 +间:首先同样也是使用 rlimit 进行 CPU 时间控制。注意它只能控制 CPU 时间,不能控制实际运行时间,所以像是 sleep 或者 IO + 阻塞之类的情况是没有办法的,所以还在额外添加了一个 alarm 来进行实际时间的限制。按照大部分比赛的管理,最终统计的时间是 CPU 时间。
- 文件句柄:同样可以通过 rlimit 来实现,以保证程序不要打开太多文件。不过其实文件这一块问题是比较多的,如果可行的话最好还是使用 stdio 然后管道重定向,完全禁止程序的文件 IO 操作。
- 访问控制:
- 通过 chroot 建立一个 jail ,将程序限制在指定目录中运行。由于是比赛程序,使用的动态链接库很有限,所以直接静态编译,从而使得运行目录中连 .so 都不需要。
- 进行必要的权限控制,例如将输入文件和程序文件本身设置为程序的运行用户只读不可写。
- 权限控制:
- 监控程序使用 root 权限运行, 完成必要准备后 fork 并切换为受限用户(比如 nobody )来运行程序。
- rlimit 设置的都是 hard limit ,非 root 无法修改。
- 正确设置运行用户之后,之前由 root 创造的 jail 受限用户是无法逃出的。
- 系统调用控制:
上 +面这些(尤其是第一步)是有很大问题,就算不是 root ,也还能做到很多事情。且不说 fork 之类的,光是那个 alarm +,就可以很轻松的把计时器取消了或者干脆主动接收这个信号。所以最根本的还是需要使用 ptrace +之类的调试器附着上程序,监控所有的系统调用,进行白名单 + 计数器(比如 exec 和 open +)过滤。这一步其实是最麻烦的(不同平台的系统调用号不一样,我们使用的是 strace 项目里头整理的调用号)。 - 更进一步:
如果你对操作系统更熟悉,那么还有一些更有趣的事情可以做。比如 Linux 下的 seccomp 功能(seccomp - Wikipedia , Chrome Linux 版就在沙盒中使用了这个技术 ),尤其是后期加入了 seccomp-bpf 之后变得更加易用。还比如 SELinux 也可以作为 defend-by-depth 的一环。另外, cgroup 其实也可以用得上。 - 编译层面:
- 很多编译工具都提供了强大的参数控制,允许你进行包括禁用内嵌 ASM 、限制连接路径之类的一些操作。通读一遍 manpage 肯定会有帮助的。
- 算法竞赛的程序推荐静态编译,之后控制起来少了动态链接库会方便许多。
- 小 +心编译期间的一些“高级功能”,比如 C 的 include 其实是有很多巧妙的用法,试试看在 Linux 下 #include +"/dev/random" 或者 #include "/dev/tty" 之类的(这两个东西会把网络上不少二流 OJ 直接卡死……)。
- 不要使用 root 用户编译,越复杂的程序越容易有 bug ,万一哪天出个编译器的 0day ……
- 考虑给编译过程同样进行时间、资源限制以作为额外防护手段。
- 架构层面:
- 运行在虚拟机/容器中
- 快照
- 心跳检测
……
你 +会发现,其实主要的限制都是在操作系统层面完成的。我认为,这样做才能带来更高的安全性,因为引发、启动危险操作的方法有很多,很难一一杜绝(包括源码分 +析、编译时限制等),但最后要让这些危险操作起效几乎都需要落回系统调用上,所以直接从这里下手也许会是个更好的办法。
我对于 Windows 不了解,不知道 Windows 下该如何实现以上的类似功能,或者是否情况完全不同,欢迎大家补充。
最后是我之前写的沙盒项目,写得很丑,尤其是 ptrace 一块目前还比较坑(64位系统下好像还无法正常工作),总的来讲还只能算是一个 demo 而已:Hexcles/Eevee · GitHub


转载自我的 blog OnlineJudge 沙箱实现思路 - virusdefender's blog (^-^)V
限制系统调用
目前常用的有 ptrace 和 seccomp。
ptrace 很惨
听说 ptrace 存在效率问题,可能会让你的代码运行时间增加很多,这个是可以简单测试看出来的。
而加载 seccomp 需要主动的在自己的代码中加载策略,也就是说需要修改已有的代码,但是去修改用户提交的代码是不大可能的。然后就想到了下面几个方法:
LD_PRELOAD hook
LD_PRELOAD加载动态链接库,然后在 so 中 hook __libc_start_main,然后就可以在用户的 main 函数前执行自己的代码了。但是如果在用户的代码中再定义__lbc_start_main函数就可以绕过,虽然网上有人说需要 -nostdlib 的编译参数,但是我实际测试并不需要。下面是沙箱的实现代码
#define _BSD_SOURCE // readlink
+#include <dlfcn.h>
+#include <stdlib.h> // exit
+#include <string.h> // strstr, memset
+#include <link.h> // ElfW
+#include <errno.h> // EPERM
+#include <unistd.h> // readlink
+#include <seccomp.h>
+#include <stdio.h>
+int syscalls_whitelist[] = {SCMP_SYS(read), SCMP_SYS(write),
+ SCMP_SYS(fstat), SCMP_SYS(mmap),
+ SCMP_SYS(mprotect), SCMP_SYS(munmap),
+ SCMP_SYS(brk), SCMP_SYS(access),
+ SCMP_SYS(exit_group)};
+typedef int (*main_t)(int, char **, char **);
+
+#ifndef __unbounded
+# define __unbounded
+#endif
+
+int __libc_start_main(main_t main, int argc,
+ char *__unbounded *__unbounded ubp_av,
+ ElfW(auxv_t) *__unbounded auxvec,
+ __typeof (main) init,
+ void (*fini) (void),
+ void (*rtld_fini) (void), void *__unbounded
+ stack_end)
+{
+
+ int i;
+ ssize_t len;
+ void *libc;
+ int whitelist_length = sizeof(syscalls_whitelist) / sizeof(int);
+ scmp_filter_ctx ctx = NULL;
+ int (*libc_start_main)(main_t main,
+ int,
+ char *__unbounded *__unbounded,
+ ElfW(auxv_t) *,
+ __typeof (main),
+ void (*fini) (void),
+ void (*rtld_fini) (void),
+ void *__unbounded stack_end);
+
+ // Get __libc_start_main entry point
+ libc = dlopen("libc.so.6", RTLD_LOCAL | RTLD_LAZY);
+ if (!libc) {
+ exit(1);
+ }
+
+ libc_start_main = dlsym(libc, "__libc_start_main");
+ if (!libc_start_main) {
+ exit(2);
+ }
+
+ ctx = seccomp_init(SCMP_ACT_KILL);
+ if (!ctx) {
+ exit(3);
+ }
+ for(i = 0; i < whitelist_length; i++) {
+ if (seccomp_rule_add(ctx, SCMP_ACT_ALLOW,
+ syscalls_whitelist[i], 0)) {
+ exit(4);
+ }
+ }
+ if (seccomp_load(ctx)) {
+ exit(5);
+ }
+ seccomp_release(ctx);
+ return ((*libc_start_main)(main, argc, ubp_av, auxvec,
+ init, fini, rtld_fini, stack_end));
+}参考 http://stackoverflow.com/a/27735456/2737403 和 https://github.com/daveho/EasySandbox
代码级别 hook
编译的时候将两个文件编译在一起,gcc sandbox.c user_code.c -ldl -lseccomp -o user_code,虽然说直接定义__libc_start_main函数会提示重复定义,但是部分库函数还是可以通过定义同名函数覆盖绕过,比如 seccomp 里面的函数、dlopen函数。
execve 前面加载策略
exceve 之前加载策略,就需要将 exceve 系统调用加白名单,有点不安全,但是可以在 seccomp 参数中指定 exceve 的执行参数,第一个参数就是文件路径,必须得匹配才行,否则就会 kill 掉。可以将指定的文件名加白名单。
#include <stdio.h>
+#include <unistd.h>
+#include <seccomp.h>
+
+int main() {
+ char file_name[30] = "/bin/ls";
+ char file_name1[30] = "xxxxxx";
+ char *argv[] = {"/", NULL};
+ char *env[] = {NULL};
+ printf("unrestricted\n");
+
+ // Init the filter
+ scmp_filter_ctx ctx;
+ ctx = seccomp_init(SCMP_ACT_ALLOW);
+
+ seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 1,
+ SCMP_A0(SCMP_CMP_NE, file_name));
+
+ seccomp_load(ctx);
+ execve(file_name, argv, env);
+ return 0;
+}如果改成execve(file_name1, argv, env);,就没法执行了。
当然要注意的是,execve 第一个参数匹配是内存地址匹配,毕竟是一个指针,而不是字符串匹配。Linux 系统开启 ASLR 之后,内存地址会随机化,用户代码几乎不可能简单的在相同的地址下面再放置一个路径。但是如果 file_name 不在栈上或者是指定地址加载的,那用户代码也可能通过 mmap 来加载到同一个地址上,可以参考 Google CTF 的一道题。
seccomp 应该怎么用
文档看 http://man7.org/linux/man-pages/man3/seccomp_rule_add.3.html 就够了,可以看到 seccomp 是支持某个参数的原始数据大小比较和掩码后数据一致比较的。
对于 C/C++ 等,我们可以开放白名单,类似 execve 这种需要特殊处理。
控制写文件
我们不期望这些程序可以写任何文件。这种想法的直觉是限制 write 的第一个参数 fd 不能大于 stderr,但是实际是可绕过的,那就是 mmap。 参考 http://man7.org/linux/man-pages/man2/mmap.2.html
页面最下面的例子修改下然后 strace 运行就会发现只需要 open 然后 mmap 也可以写文件的。
正确的方法是限制 open,不能带写权限。open 的 man page 中说
The argument flags must include one of the following access modes: O_RDONLY, O_WRONLY, or O_RDWR
所以这里就需要之前的掩码后比较了,其实掩码操作就是使用掩码和原数据进行与操作,SCMP_CMP(1, SCMP_CMP_MASKED_EQ, O_WRONLY | O_RDWR, 0) 就是说这两位上都是0才可以通过。
和 mmap 类似的是 creat 系统调用,也可以创建一个文件。
这种问题的根本解决办法是修改文件系统的用户权限。
__x32_compat 系统调用
https://github.com/torvalds/linux/blob/master/arch/x86/entry/syscalls/syscall_64.tbl#L353 有一些 __x32_compat 开头的系统调用,很容易忽略它们,没有加入黑名单,这些系统调用和不带 _x32_compat 的用法基本一致。
资源占用的限制
CPU 时间限制,是 setrlimit 还是 setitimer
主要是的区别是子进程能否继承限制,进程能否捕获超时错误。
当 setitimer 定时器计时结束时,系统就会给进程发送一个信号。
需要关心的两个计数器分别是 ITIMER_REAL 进程实际运行时间计数器,结束的时候发送 SIGALRM 信号;ITIMER_VIRTUAL 进程 CPU 时间计数器,结束的时候发送 SIGVTALRM 信号。我们设置好定时器之后,如果捕获到了对应的信号,说明当前进程运行超时。
具体实现代码如下
int set_timer(int sec, int ms, int is_cpu_time) {
+ struct itimerval time_val;
+ time_val.it_interval.tv_sec = time_val.it_interval.tv_usec = 0;
+ time_val.it_value.tv_sec = sec;
+ time_val.it_value.tv_usec = ms * 1000;
+ if (setitimer(is_cpu_time?ITIMER_VIRTUAL:ITIMER_REAL, &time_val, NULL)) {
+ LOG_FATAL("setitimer failed, errno %d", errno);
+ return SETITIMER_FAILED;
+ }
+ return SUCCESS;
+}但是有一点是需要注意的,setitimer 不能限制子进程的 CPU 和实际运行时间。
在部分只限制资源占用而不启用沙箱的场景下,这可能导致资源限制失效,因为进程可以取消这个设定。
Linux 中 setrlimit 函数可以用来限制进程的资源占用, 其中支持 RLIMIT_CPU、RLIMIT_AS 等参数, 同时子进程会继承父进程的设置。RLIMIT_CPU 也可以控制进程 CPU 时间, 所以要设置为 CPU 时间向上取整的值,然后和最后获取的时间再比较。
限制内存和最大输出大小
RLIMIT_AS 是限制进程最大内存地址空间,超过这个地址空间的将不能 分配成功,影响 brk、mmap、mremap 等系统调用。 RLIMIT_FSIZE 是限制进程最大输出或者写文件的大小,估计是限制了 write 等。
实际运行时间
这个也很重要,如果一个进程啥都不做只 sleep 的话,CPU 时间几乎不会超,这里我的方案是新开一个线程一直监视某个 PID,超时就 kill 掉。
RLIMIT_NPROC 有点坑
很多人都知道 while(1) fork() 可以卡死机器,怎么防?尤其是 go 这类这种天生就要开线程的语言。
+ The maximum number of processes (or, more precisely on Linux, threads) +that can be created for the real user ID of the calling process. Upon +encountering this limit, fork(2) fails with the error EAGAIN
如果简单的使用 nproc 限制是不可以的,原因是 real user ID 这个其实不仅仅是进程的,和用户也有关。一个用户已经有10个进程了,那你给进程设置 nproc=10 是没用的,因为已经满了,而设置更低的数字可能导致进程无法启动。
也许给每个进程都设置一个单独的用户可破?没有试
还有哪里容易出现问题
编译器安全
这是一个容易被忽视的方面,目前已知的主要有以下几种。
- 引用某些可以无限输出的文件,比如
#include</dev/random>,编译器会一直读取, 导致卡死 - 让编译器产生大量的错误信息,比如下面一段代码,可以让 g++ 编译器产生数 G 的错误日志
int main() {
+ struct x struct z<x(x(x(x(x(x(x(x(x(x(x(x(x(x(x(y,x(y><y*,x(y*w>v<y*,w,x{}
+ return 0;
+}处理方法就是编译器运行的时候也要控制 CPU 时间和实际运行时间还有最大输出,同时使用编译器参数 -fmax-errors=N 来控制最大错误数量
- C++ 的模板元编程,部分代码是编译期执行的,可以构造出让编译器产生大量计算的代码。类似的有 Python 的编译器常量优化等等。
- 引用一些敏感文件可能导致信息泄露,比如
#include</etc/shadow/>或者测试用例等,会在编译错误的信息中泄露文件开头的内容。需要给编译器和运行代码设置单独的用户。
上面说的基础环境其实都在 Docker 里面
Docker 默认会屏蔽一些系统调用和 capability,所以上面的很多方案都是基于这个前提的,否则需要自己处理 Docker 默认屏蔽的系统调用调用黑名单和降权。
开源 https://github.com/QingdaoU/Judger
参考
- http://manpages.ubuntu.com/manpages/saucy/man3/seccomp_rule_add.3.html
- https://filippo.io/linux-syscall-table/
- https://www.zhihu.com/question/23067497
再加个广告,我们开发的 OnlineJudge 系统 QingdaoU/OnlineJudge: Open source online judge based on Python, Django and Docker. 也开源了,欢迎给个 star。
1. Then Google Native Client
后来遇见了chrome,在看其native client的实现,其实就是OJ后台的一套sandbox系统。
核心部分,构建的2套sandbox
• inner sandbox: binary validation
• outer sandbox: OS system-call interception
--> inner sandbox
Protection Rule For Inner Sandbox


Based on systrace.
Reference:
http://static.googleusercontent.com/media/research.google.com/en//pubs/archive/34913.pdf
http://www.citi.umich.edu/u/provos/papers/systrace.pdf
2. ZeroVM
zerovm/zerovm · GitHub
APP Sandbo领域新出生的创业公司,核心思路如下
ZeroVM creates a sandbox around a single process,
using technology based on Google Native Client + (NaCl). The sandbox ensures that the application executed cannot access + data in the host operating system, so it is safe to execute untrusted +code.


所以,如果不想自己造轮子,可以用ZeroVM。过几天,把我那个系统试试移到ZeroVM上~~
3. Qubes OS
看下architecture 感受下,
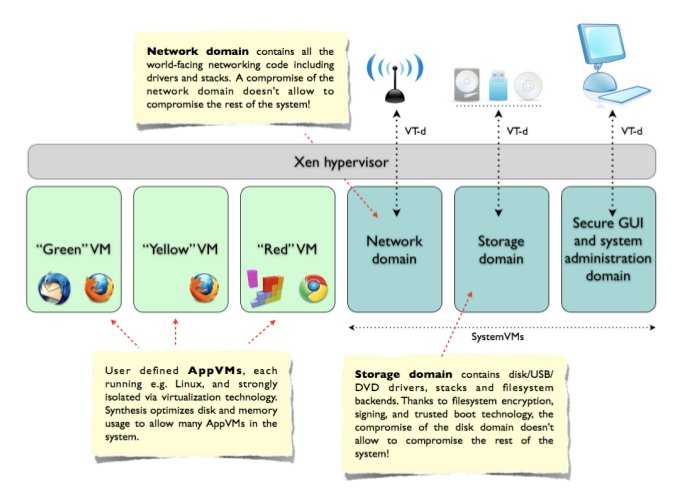

它充分利用了虚拟化技术(基于安全虚拟机Xen),所有用户应用程序都运行在AppVM(基于Linux的轻量级虚 拟机)中,彼此隔离。
也能利用,但是用来跑OJ可能有点大材小用了。
欢迎讨论~
给ZOJ写过Patch的来回答一下。
ZOJ的沙箱是ptrace。但是ptrace的规则是硬写进去的,规则写的也比较复杂。比如:我记得当时glibc升级之后,由于某些安全功能(貌似是pointer guard?),需要在程序启动的时候读取/dev/urandom。
沙箱的内存控制是简单的setrlimit。
ptrace倒是并不慢,因为OJ的题目大部分很少频繁的调用system call。如果很频繁,那恐怕那个程序本身就是攻击的恶意程序。
前 +面说用语言环境运行时而非动态沙箱的解决方法,我觉得做起来难度比较大。我对JIT +Spraying攻击不了解,但是个人感觉语言运行时的JIT是一个很大的attack +surface。而且还有,OJ里用Java和C#的比较少,部分原因是IO库比较慢,而且有些OJ问题对性能要求实在是太高了,OJ提交者往往喜欢对一 +切过程都有控制。
如果说其他的选择,我会觉得虚拟化是个很好的选择。唯一的attack surface就是虚拟机和硬件本身曾经在我们学校里做过online judge,用的好像是POJ当时的一个demo,在Windows上弄的。
当时做法也没考虑太多,先是建立一个guest账户,用guest账户运行代码,所有权限全限制在某一个盘里,大不了就废了一个盘,也无所谓。
反对匿名用户说的不危险,实际上OJ这种东西太危险了,允许上传+执行权限,危险特别大。
把网页部分和代码分开,我忘记当时我们是用一个账户还是两个账户,反正网页的路径是一个很古怪的路径,这样入侵者也不太好在页面上挂马,我记得页面好像是PHP或者JSP之类的。
在编译器和连接器上做了点手脚,一共有几层防御:
第一层是把标准库里的头文件先都注释掉,包括文件操作、还有system、网络操作等等,对于一般的菜鸟就足够了,大多数菜鸟没了头文件都不知道该怎么办。
第二层是彻底干掉C++,我记得当时我们用的是MinGW,直接不安装G++组件,因为G++的库太复杂了,像cin/cout这些不好控制
第三层是修改链接库,当时在大学时候技术也很一般,我记得方法很糙,就是找到lib文件,用winhex之类的工具打开,找到fopen这些直接把所有敏感的字符串全换掉。实际上允许用的就string库和stdlib这些,这样连接器也找不到符号。
这样下来入侵者要是想通过标准库的话基本就很困难了。
在上传页面上也要做限制,比如,禁用汇编内联,直接通过过滤字符串asm实现,必要的时候做一个WindowsAPI的过滤表,在上传代码的时候就过滤掉所有WindowsAPI,但这个很困难,因为代码里可以不用字符串。
这样折腾下来,基本上把主要的入口都封死了。然后关键的一步:服务器网卡上关掉所有的端口,仅限于某几个端口开放(80/8080之类的)。
但是现在想想,并不是特别的安全,比如上传代码如果自己实现一套LoadLibrary然后直接调用WindowsAPI的话,还是可以入侵的。
至于说限制运行时间的,这个太困难了,1秒钟够执行很多指令了,没意义。
更稳妥的方法是限制注册,但这已经不是技术范畴了。
我能记得的就这些了。








